
Buy fast & affordable proxy servers. Get 10 proxies today for free.
Download our Proxy Server Extension
Products
© Webshare Proxy
payment methods





TL;DR
Google Maps is one of the most powerful sources of real-world business data. Whether you're generating leads, analyzing competitors for local SEO, or building location-based datasets, Google Maps results offer rich, high-intent information. Automating this data collection transforms hundreds of business listings into structured spreadsheets you can easily filter, sort, and analyze. In this guide, you’ll learn how to build a Google Maps scraper in Python and turn raw listings into clean data ready for SEO research, lead generation, and more.
Before building and running the Google Maps scraper, ensure your environment is properly set up with the required Python version, libraries, and proxy configuration.
python --versionpip install playwrightplaywright install chromiumjson, csv - Handles data export.time, random - Adds human-like delays.re - Uses regex for parsing coordinates.urllib.parse - Encodes URLs safely.Once your prerequisites are ready and your environment is set up, you can begin scraping business listings from Google Maps. Below are the steps you’ll follow to run the scraper and customize the data you want to extract.
Start by creating a list of Google Maps search terms you want to scrape. These can be location-based keywords such as:
search_queries = [
"Restaurants in New York",
"Plumbers in London",
"Gyms near me"
]Decide how many business listings you want to extract for each search keyword:
max_results_per_query = 10Increase this number if you want deeper coverage for each search results page.
You can include an optional review extraction toggle in the scraper and enable it if you want to collect review text:
SCRAPE_REVIEWS = TrueIf you only want business details and no reviews:
SCRAPE_REVIEWS = FalseThis toggle is passed into the scraper when you initialize it:
scraper = GoogleMapsScraper(scrape_reviews=SCRAPE_REVIEWS)Once your configuration is ready, start the scraper by calling:
businesses = await scraper.scrape_queries(
queries=search_queries,
use_proxy=USE_PROXY,
proxy_country=PROXY_COUNTRY,
max_results_per_query=max_results_per_query
)
During this process, the scraper will:
After scraping is complete, save the results in structured formats:
scraper.save_to_json(businesses, json_filename)
scraper.save_to_csv(businesses, csv_filename)
Here’s the complete code:
import asyncio
import json
import csv
import time
import random
import re
from datetime import datetime
from playwright.async_api import async_playwright
from urllib.parse import quote
class GoogleMapsScraper:
def __init__(self, scrape_reviews=False):
self.browser = None
self.page = None
self.playwright = None
self.base_url = "https://www.google.com/maps"
self.scrape_reviews = scrape_reviews
self.selectors = {
'business_card': 'div[role="article"]',
'title': '.qBF1Pd.fontHeadlineSmall',
'rating': '.MW4etd',
'reviews_count': '.UY7F9',
'address': '.W4Efsd span',
'business_link': 'a.hfpxzc',
'phone_number': 'button[data-item-id*="phone"] .Io6YTe',
'website_url': 'a[data-item-id="authority"]',
'review_text': '.wiI7pd',
'review_container': '.MyEned',
'review_expand_button': 'button.w8nwRe.kyuRq',
}
async def setup_browser(self, use_proxy=False, proxy_country='US'):
"""Setup browser with optional proxy"""
await self.close()
self.playwright = await async_playwright().start()
launch_options = {
'headless': True,
'args': [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-blink-features=AutomationControlled',
]
}
# Proxy configuration - easily toggleable
if use_proxy:
username = f"username-{proxy_country}-rotate" # Enter username
password = "password" # Enter password
launch_options['proxy'] = {
'server': 'http://p.webshare.io:80',
'username': username,
'password': password
}
self.browser = await self.playwright.chromium.launch(**launch_options)
context = await self.browser.new_context(
viewport={'width': 1920, 'height': 1080},
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
)
await context.add_init_script("""
Object.defineProperty(navigator, 'webdriver', {get: () => undefined});
""")
self.page = await context.new_page()
async def random_delay(self, min_seconds=1, max_seconds=3):
"""Random delay between actions"""
delay = random.uniform(min_seconds, max_seconds)
await asyncio.sleep(delay)
async def extract_coordinates_from_url(self, url):
"""Extract coordinates from Google Maps URL"""
try:
if '!3d' in url and '!4d' in url:
lat_match = re.search(r'!3d(-?\d+\.\d+)', url)
lng_match = re.search(r'!4d(-?\d+\.\d+)', url)
if lat_match and lng_match:
return {
'latitude': float(lat_match.group(1)),
'longitude': float(lng_match.group(1))
}
except:
pass
return None
async def extract_address_from_card(self, business_card):
"""Extract address from business card"""
try:
address_elements = await business_card.query_selector_all('.W4Efsd span')
for element in address_elements:
text = await element.text_content()
if text and text.strip():
# Look for address patterns
if (any(char.isdigit() for char in text) and
any(indicator in text for indicator in ['St', 'Ave', 'Rd', 'Street', 'Avenue', 'Road', 'Broadway'])):
# Clean up the address
cleaned_address = re.sub(r'^[·\s]+', '', text.strip())
return cleaned_address
except:
pass
return ""
async def expand_review_if_needed(self, review_container):
"""Click 'More' button to expand truncated reviews"""
try:
# Check if there's a "More" button and click it
expand_button = await review_container.query_selector(self.selectors['review_expand_button'])
if expand_button:
await expand_button.click()
await self.random_delay(0.5, 1)
return True
except Exception as e:
# Sometimes the click might fail, that's okay
pass
return False
async def extract_reviews(self):
"""Extract review texts from business page"""
reviews = []
if not self.scrape_reviews:
return reviews
try:
# Wait for reviews to load
try:
await self.page.wait_for_selector(self.selectors['review_container'], timeout=15000)
except:
print("No review containers found")
return reviews
# Scroll to load more reviews
await self.page.evaluate("""
const reviewSection = document.querySelector('[data-section-id="reviews"]');
if (reviewSection) {
reviewSection.scrollIntoView();
}
""")
await self.random_delay(2, 3)
# Extract review containers
review_containers = await self.page.query_selector_all(self.selectors['review_container'])
for container in review_containers[:5]: # Limit to 5 reviews
try:
# Expand review if it has a "More" button
await self.expand_review_if_needed(container)
# Extract review text from the main review text element
review_text_element = await container.query_selector(self.selectors['review_text'])
if review_text_element:
review_text = await review_text_element.text_content()
if review_text and review_text.strip():
reviews.append(review_text.strip())
except Exception as e:
print(f"Error extracting individual review: {e}")
continue
except Exception as e:
print(f"Error extracting reviews: {e}")
return reviews
async def extract_phone_website_reviews(self, business_url):
"""Extract phone number, website, and reviews from business URL"""
phone = ""
website = ""
reviews = []
if not business_url:
return phone, website, reviews
try:
# Navigate directly to the business page
await self.page.goto(business_url, wait_until='domcontentloaded', timeout=15000)
await self.random_delay(2, 3)
# Wait for business details to load
try:
await self.page.wait_for_selector('[data-item-id]', timeout=10000)
except:
print("Business details didn't load properly")
# Extract phone number
try:
phone_element = await self.page.query_selector(self.selectors['phone_number'])
if phone_element:
phone = await phone_element.text_content()
except Exception as e:
print(f"Error extracting phone: {e}")
# Extract website
try:
website_element = await self.page.query_selector(self.selectors['website_url'])
if website_element:
website_href = await website_element.get_attribute('href')
if website_href:
website = website_href
except Exception as e:
print(f"Error extracting website: {e}")
# Extract reviews if enabled
if self.scrape_reviews:
reviews = await self.extract_reviews()
except Exception as e:
print(f"Error extracting business details: {e}")
return phone, website, reviews
async def extract_business_basic_data(self, business_card):
"""Extract basic business data without clicking into details"""
business_data = {}
try:
# Extract title
title_element = await business_card.query_selector(self.selectors['title'])
business_data['title'] = await title_element.text_content() if title_element else ""
if not business_data['title']:
return None
# Extract rating
rating_element = await business_card.query_selector(self.selectors['rating'])
if rating_element:
rating_text = await rating_element.text_content()
try:
business_data['rating'] = float(rating_text) if rating_text else None
except:
business_data['rating'] = None
# Extract reviews count
reviews_element = await business_card.query_selector(self.selectors['reviews_count'])
if reviews_element:
reviews_text = await reviews_element.text_content()
reviews_match = re.search(r'\(([\d,]+)\)', reviews_text)
if reviews_match:
try:
reviews_count = reviews_match.group(1).replace(',', '')
business_data['reviews_count'] = int(reviews_count)
except:
business_data['reviews_count'] = None
# Extract address
business_data['address'] = await self.extract_address_from_card(business_card)
# Extract business URL for coordinates
business_link = await business_card.query_selector(self.selectors['business_link'])
if business_link:
business_url = await business_link.get_attribute('href')
if business_url:
full_url = f"https://www.google.com{business_url}" if business_url.startswith('/') else business_url
business_data['business_url'] = full_url
business_data['coordinates'] = await self.extract_coordinates_from_url(full_url)
# Initialize empty fields
business_data['phone_number'] = ""
business_data['website_url'] = ""
business_data['reviews'] = []
except Exception as e:
print(f"Error extracting basic business data: {e}")
return None
return business_data
async def scrape_search_results(self, query, max_results=10):
"""Scrape business listings for a search query"""
businesses = []
try:
# Use Google Maps search URL
encoded_query = quote(query)
search_url = f"https://www.google.com/maps/search/{encoded_query}"
print(f"Navigating to: {search_url}")
await self.page.goto(search_url, wait_until='domcontentloaded', timeout=30000)
await self.random_delay(3, 5)
# Handle cookie consent
try:
cookie_button = await self.page.query_selector('button:has-text("Accept all"), button:has-text("I agree")')
if cookie_button:
await cookie_button.click()
await self.random_delay(1, 2)
except:
pass
# Wait for business cards
try:
await self.page.wait_for_selector(self.selectors['business_card'], timeout=15000)
except:
print("No business cards found")
return businesses
# Scroll to load more results
await self.page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await self.random_delay(2, 3)
# Extract all business cards and get basic data first
business_cards = await self.page.query_selector_all(self.selectors['business_card'])
basic_business_data = []
for i, card in enumerate(business_cards[:max_results]):
business_data = await self.extract_business_basic_data(card)
if business_data:
basic_business_data.append(business_data)
await self.random_delay(1, 2)
# Now extract phone, website, and reviews for each business
for i, business_data in enumerate(basic_business_data):
if business_data.get('business_url'):
phone, website, reviews = await self.extract_phone_website_reviews(business_data['business_url'])
business_data['phone_number'] = phone
business_data['website_url'] = website
business_data['reviews'] = reviews
business_data['search_query'] = query
business_data['scraped_at'] = datetime.now().isoformat()
businesses.append(business_data)
await self.random_delay(2, 4) # Longer delay between detail extractions
except Exception as e:
print(f"Error scraping search results for '{query}': {e}")
return businesses
async def scrape_queries(self, queries, use_proxy=False, proxy_country='US', max_results_per_query=10):
"""Scrape business listings for multiple search queries"""
all_businesses = []
await self.setup_browser(use_proxy=use_proxy, proxy_country=proxy_country)
try:
for i, query in enumerate(queries):
print(f"\n{'='*50}")
print(f"Processing query {i+1}/{len(queries)}: '{query}'")
print(f"{'='*50}")
businesses = await self.scrape_search_results(query, max_results_per_query)
all_businesses.extend(businesses)
print(f"Completed '{query}': {len(businesses)} businesses found")
# Random delay between queries
if i < len(queries) - 1:
delay = random.uniform(3, 6)
print(f"Waiting {delay:.1f} seconds before next query...")
await asyncio.sleep(delay)
finally:
await self.close()
return all_businesses
async def close(self):
"""Close browser and playwright"""
try:
if self.page:
await self.page.close()
self.page = None
except:
pass
try:
if self.browser:
await self.browser.close()
self.browser = None
except:
pass
try:
if self.playwright:
await self.playwright.stop()
self.playwright = None
except:
pass
def save_to_json(self, businesses, filename):
"""Save businesses to JSON file"""
with open(filename, 'w', encoding='utf-8') as f:
json.dump(businesses, f, indent=2, ensure_ascii=False)
print(f"Saved {len(businesses)} businesses to {filename}")
def save_to_csv(self, businesses, filename):
"""Save businesses to CSV file"""
if not businesses:
print("No businesses to save")
return
fieldnames = ['search_query', 'title', 'address', 'phone_number', 'website_url',
'rating', 'reviews_count', 'business_url', 'latitude', 'longitude', 'scraped_at']
# Add reviews field only if reviews scraping is enabled
if any('reviews' in business for business in businesses):
fieldnames.append('reviews')
with open(filename, 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for business in businesses:
row = business.copy()
# Flatten coordinates for CSV
if row.get('coordinates'):
row['latitude'] = row['coordinates'].get('latitude')
row['longitude'] = row['coordinates'].get('longitude')
else:
row['latitude'] = None
row['longitude'] = None
# Remove the coordinates object for CSV
if 'coordinates' in row:
del row['coordinates']
writer.writerow(row)
print(f"Saved {len(businesses)} businesses to {filename}")
async def main():
# === USER CONFIGURATION ===
# 1. User inputs list of search queries
search_queries = ["Restaurants in New York", "Plumbers in London", "Gyms near me"]
# 2. Configure scraping parameters
max_results_per_query = 10
# REVIEWS TOGGLE - Set to True to scrape reviews, False to skip reviews
SCRAPE_REVIEWS = True # Change this to False if you don't want reviews
# PROXY TOGGLE - Set to True to use proxy
USE_PROXY = True
PROXY_COUNTRY = 'US' # Change this to your desired country (US, UK, CA, DE, etc.)
# Initialize scraper with reviews toggle
scraper = GoogleMapsScraper(scrape_reviews=SCRAPE_REVIEWS)
print("Starting Google Maps Scraper")
print(f"Queries: {search_queries}")
print(f"Max results per query: {max_results_per_query}")
print("=" * 50)
# Scrape businesses
start_time = time.time()
businesses = await scraper.scrape_queries(
queries=search_queries,
use_proxy=USE_PROXY,
proxy_country=PROXY_COUNTRY,
max_results_per_query=max_results_per_query
)
end_time = time.time()
# Save results
if businesses:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
json_filename = f"google_maps_{timestamp}.json"
csv_filename = f"google_maps_{timestamp}.csv"
scraper.save_to_json(businesses, json_filename)
scraper.save_to_csv(businesses, csv_filename)
# Print summary
print(f"\n{'='*50}")
print("SCRAPING COMPLETED!")
print(f"{'='*50}")
print(f"Total businesses found: {len(businesses)}")
for query in search_queries:
count = len([b for b in businesses if b['search_query'] == query])
print(f" - '{query}': {count} businesses")
else:
print("No businesses found!")
# Run the scraper
await main()
Note: This code uses await main() which works in Google Colab and Jupyter notebooks. For regular Python scripts, use this instead:
if __name__ == "__main__":
asyncio.run(main())
The console output is as:

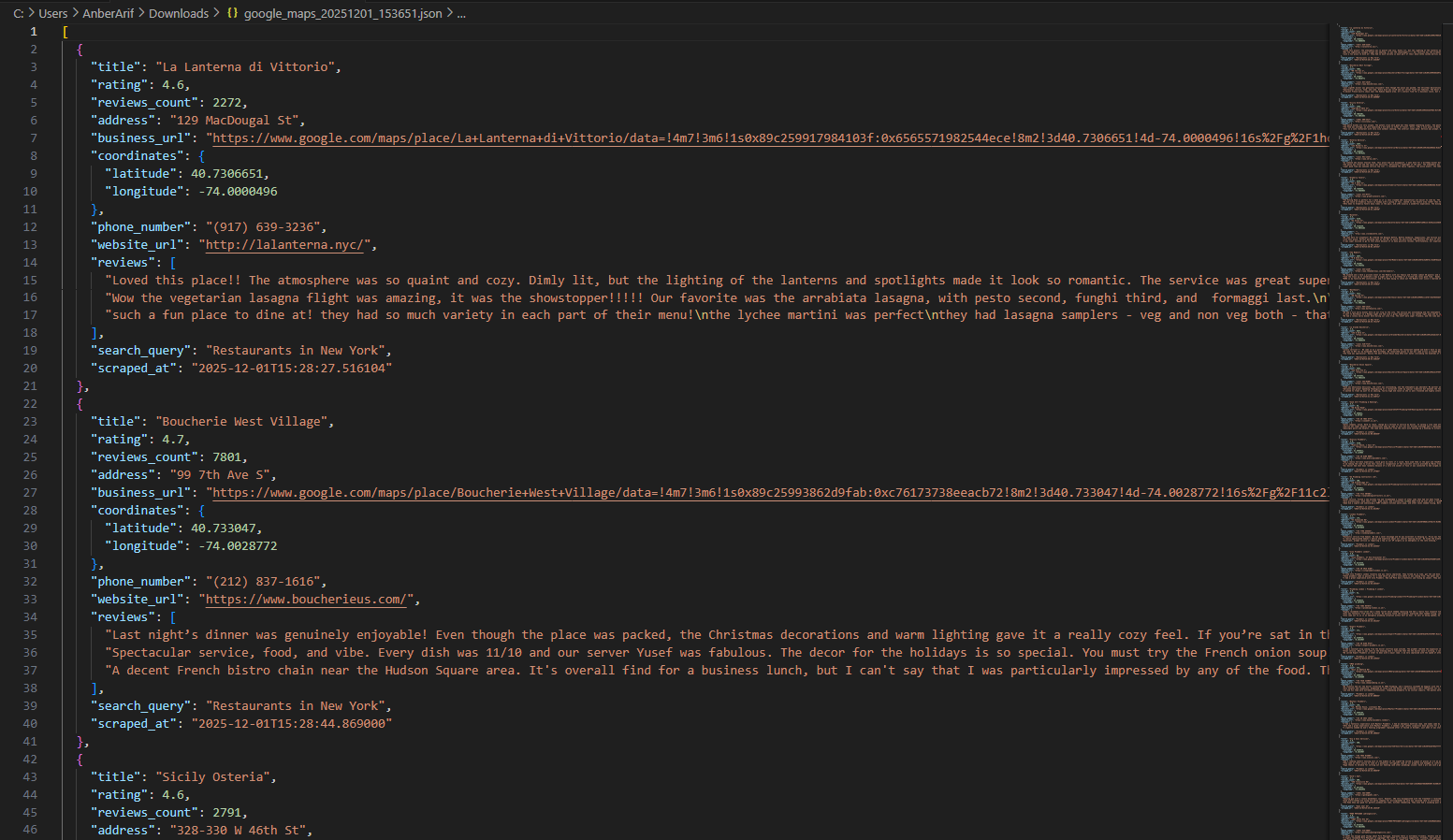
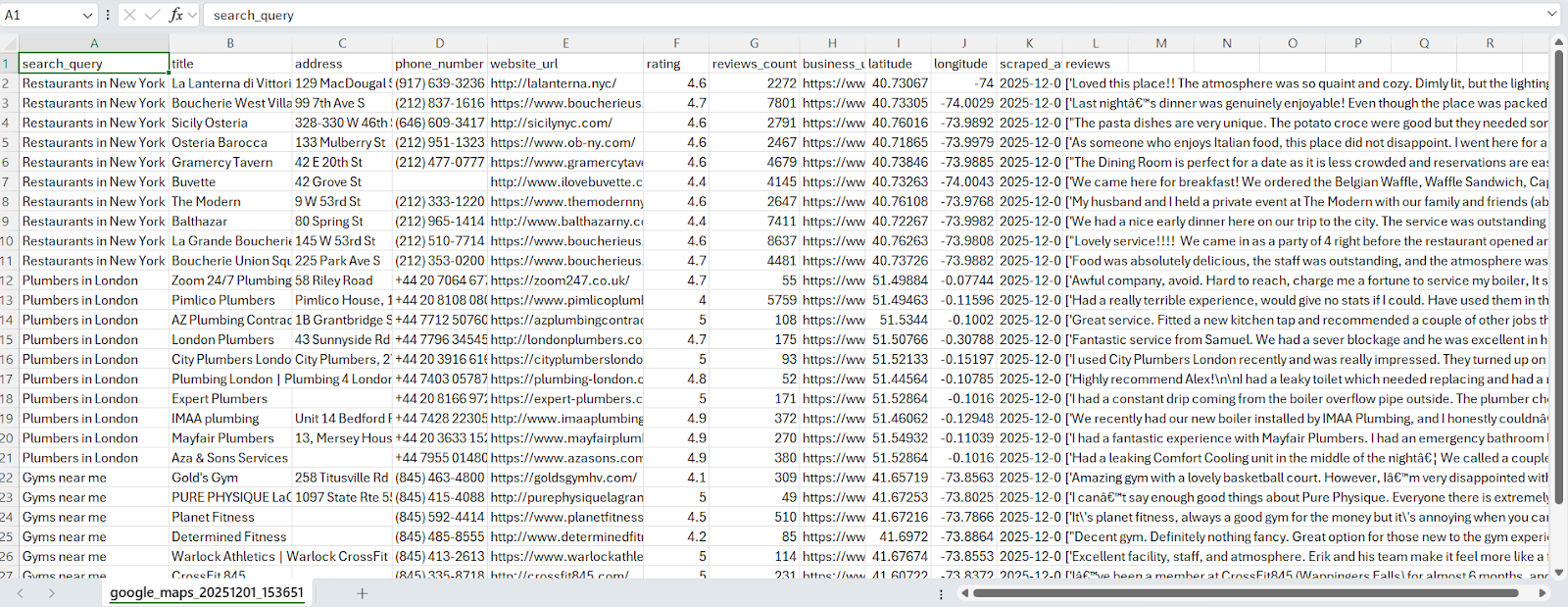
In this guide, we built a Google Maps scraper using Python and Playwright, enhanced with Webshare rotating residential proxies to avoid Google’s anti-bot mechanisms. The scraper collects structured business data – including names, addresses, phone numbers, websites, ratings, review counts, and coordinates – and can optionally extract text reviews for deeper insights. By automating Google Maps data extraction, you can quickly generate organized JSON or CSV datasets for lead generation or local SEO research, all while minimizing CAPTCHAs, IP blocks, and other anti-bot challenges.
