
Buy fast & affordable proxy servers. Get 10 proxies today for free.
Download our Proxy Server Extension
Products
© Webshare Proxy
payment methods





TL;DR
Learn how to scrape Google Play Store data using Python – from search results to detailed app information and user reviews. We’ll build three practical scrapers:
In this guide, you’ll learn how to programmatically extract this data using Python libraries like Requests and BeautifulSoup, along with Webshare proxies to avoid IP bans.
Before you start building the Google Play scrapers, make sure your environment is set up properly.
pip install requests beautifulsoup4pip install pandas lxmlLet’s build a Python scraper that extracts app listings directly from Google Play search results. The goal is to collect structured data such as app names, links, ratings, and prices – all stored neatly in a CSV file.
Begin by defining a list of keywords that represent the types of apps you want to scrape. These could be industry-specific, such as “crypto wallet,” “fitness tracker,” or “photo editor.” For each keyword, the script automatically builds a URL in this format:
https://play.google.com/store/search?q=<your-term>&c=apps&hl=enEach URL represents a results page containing apps that match the search term.
Before sending requests, establish a requests session with a custom User-Agent to mimic a real browser. To avoid temporary IP bans from Google, route all requests through Webshare proxies.
After processing all search terms, remove the duplicate entries based on the app url and write the results to a file. Run the script and you’ll find a file in your working directory.
Here’s the complete code:
import requests
from bs4 import BeautifulSoup
import urllib.parse
import csv
import re
def scrape_play_store_apps_enhanced(search_terms):
"""Enhanced version with fixed rating extraction"""
proxies = {
"http": "http://username:password@p.webshare.io:80",
"https": "http://username:password@p.webshare.io:80"
}
session = requests.Session()
session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
})
all_apps = []
for term in search_terms:
query = urllib.parse.quote(term)
url = f"https://play.google.com/store/search?q={query}&c=apps&hl=en"
print(f"Scraping: {url}")
try:
response = session.get(url, proxies=proxies, timeout=15)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
# Multiple approaches to find app containers
apps = []
# Method 1: Common container classes for Google Play apps
apps.extend(soup.find_all('div', class_='ULeU3b'))
apps.extend(soup.find_all('div', class_='VfPpkd-WsjYwc'))
# Method 2: Look for divs containing app cards
if not apps:
app_cards = soup.find_all('div', class_=lambda x: x and 'cover' in x.lower())
apps.extend(app_cards)
# Method 3: Find by app link pattern
if not apps:
app_links = soup.find_all('a', href=lambda x: x and '/store/apps/details?id=' in x)
for link in app_links:
parent_card = link.find_parent('div')
if parent_card and parent_card not in apps:
apps.append(parent_card)
for app in apps:
try:
# Extract title with multiple selectors
title = 'N/A'
title_selectors = [
'div.Epkrse', 'div.nnK0zc', 'div.cXFu1',
'span.DdYX5', 'div[aria-label]', 'h3'
]
for selector in title_selectors:
title_elem = app.select_one(selector)
if title_elem and title_elem.get_text(strip=True):
title = title_elem.get_text(strip=True)
break
# Extract app URL
app_url = 'N/A'
link_elem = app.find('a', href=True)
if link_elem:
href = link_elem['href']
if '/store/apps/details?id=' in href:
app_url = f"https://play.google.com{href}" if href.startswith('/') else href
# Skip if no valid URL found
if app_url == 'N/A':
continue
# Extract cover/logo URL
cover_url = 'N/A'
logo_url = 'N/A'
img_elem = app.find('img', src=True)
if img_elem:
cover_url = img_elem.get('src') or img_elem.get('data-src') or 'N/A'
logo_url = cover_url
# EXTRACT RATING - FIXED BASED ON IMAGE
reviews_avg = 'N/A'
# Method 1: Look for rating in the format "4.4 ★"
rating_text = app.get_text()
rating_match = re.search(r'(\d+\.\d+)\s*★', rating_text)
if rating_match:
reviews_avg = rating_match.group(1)
else:
# Method 2: Look for numeric pattern near star symbols
rating_match = re.search(r'(\d+\.\d+)\s*[★⭐]', rating_text)
if rating_match:
reviews_avg = rating_match.group(1)
else:
# Method 3: Look for common rating classes
rating_selectors = [
'div[aria-label*="star"]',
'span[aria-label*="star"]',
'div.TT9eCd',
'div.w2kbF',
'div.Yx2Aie',
'span.rating'
]
for selector in rating_selectors:
rating_elem = app.select_one(selector)
if rating_elem:
rating_text = rating_elem.get_text(strip=True)
num_match = re.search(r'(\d+\.\d+)', rating_text)
if num_match:
reviews_avg = num_match.group(1)
break
# If still not found, try to find any numeric rating in the app card
if reviews_avg == 'N/A':
all_text = app.get_text()
# Look for patterns like "4.4" in the text
number_pattern = re.findall(r'\b\d+\.\d+\b', all_text)
if number_pattern:
# Assume the first number between 1.0 and 5.0 is the rating
for num in number_pattern:
if 1.0 <= float(num) <= 5.0:
reviews_avg = num
break
# Extract price
price = 'Free'
price_selectors = [
'span.VfPpfd',
'span.ePXqnb',
'span.T4LgNb',
'button[aria-label*="$"]',
'span[class*="price"]'
]
for selector in price_selectors:
price_elem = app.select_one(selector)
if price_elem:
price_text = price_elem.get_text(strip=True)
if price_text and price_text.lower() not in ['install', '']:
# Clean price text
price = re.sub(r'\s+', ' ', price_text).strip()
break
all_apps.append({
'title': title,
'app_url': app_url,
'cover_url': cover_url,
'logo_url': logo_url,
'reviews_avg': reviews_avg,
'price': price
})
print(f"✓ Found: {title} | Rating: {reviews_avg} | Price: {price}")
except Exception as e:
print(f"Error parsing app: {e}")
continue
print(f"Found {len([a for a in all_apps if a['title'] != 'N/A'])} apps for '{term}'")
except Exception as e:
print(f"Error while processing '{term}': {e}")
continue
# Remove duplicates based on app_url
unique_apps = []
seen_urls = set()
for app in all_apps:
if app['app_url'] not in seen_urls and app['title'] != 'N/A':
seen_urls.add(app['app_url'])
unique_apps.append(app)
# Write data to CSV
with open('google_play_apps.csv', 'w', newline='', encoding='utf-8') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=[
'title', 'app_url', 'cover_url', 'logo_url', 'reviews_avg', 'price'
])
writer.writeheader()
writer.writerows(unique_apps)
print(f"\nCSV file created successfully with {len(unique_apps)} unique app entries.")
# Show sample of ratings found
print("\nSample ratings found:")
for app in unique_apps[:5]:
print(f" {app['title']}: {app['reviews_avg']}")
return unique_apps
# Simple version with just the rating fix
def scrape_play_store_apps_simple(search_terms):
"""Simple version focused on fixing the rating extraction"""
proxies = {
"http": "http://username:password@p.webshare.io:80",
"https": "http://username:password@p.webshare.io:80"
}
session = requests.Session()
session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
all_apps = []
for term in search_terms:
query = urllib.parse.quote(term)
url = f"https://play.google.com/store/search?q={query}&c=apps&hl=en"
print(f"Scraping: {url}")
try:
response = session.get(url, proxies=proxies, timeout=15)
soup = BeautifulSoup(response.content, 'html.parser')
# Find all app containers
apps = soup.find_all('div', class_=['ULeU3b', 'VfPpkd-WsjYwc'])
for app in apps:
# Extract title
title_elem = app.find('div', class_=['Epkrse', 'nnK0zc'])
title = title_elem.get_text(strip=True) if title_elem else 'N/A'
# Extract app URL
link_elem = app.find('a', href=True)
app_url = f"https://play.google.com{link_elem['href']}" if link_elem else 'N/A'
# Extract cover image
img_elem = app.find('img', src=True)
cover_url = img_elem['src'] if img_elem else 'N/A'
logo_url = cover_url
# EXTRACT RATING - SIMPLE FIX
reviews_avg = 'N/A'
app_text = app.get_text()
# Look for pattern like "4.4 ★" from your image
rating_match = re.search(r'(\d+\.\d+)\s*★', app_text)
if rating_match:
reviews_avg = rating_match.group(1)
# Extract price
price_elem = app.find('span', class_=['VfPpfd', 'ePXqnb'])
price = price_elem.get_text(strip=True) if price_elem else 'Free'
if title != 'N/A' and app_url != 'N/A':
all_apps.append({
'title': title,
'app_url': app_url,
'cover_url': cover_url,
'logo_url': logo_url,
'reviews_avg': reviews_avg,
'price': price
})
except Exception as e:
print(f"Error with '{term}': {e}")
continue
# Save to CSV
with open('google_play_apps.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=['title', 'app_url', 'cover_url', 'logo_url', 'reviews_avg', 'price'])
writer.writeheader()
writer.writerows(all_apps)
print(f"Saved {len(all_apps)} apps to google_play_apps.csv")
# Example usage
if __name__ == "__main__":
search_terms = [
"bitcoin exchange",
"ethereum exchange",
"crypto wallet",
"binance",
"coinbase"
]
# Use the enhanced version for best results
scrape_play_store_apps_enhanced(search_terms)Here’s how the output looks like:
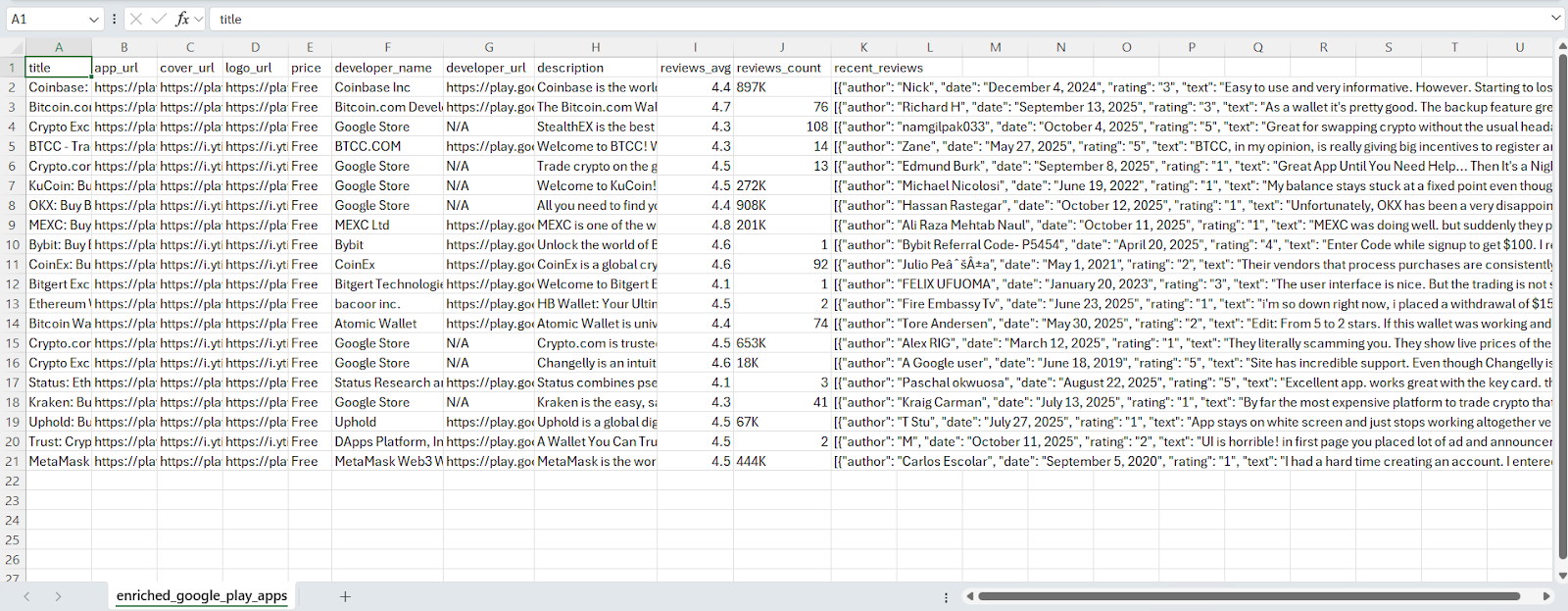
The generated csv is as:
In this section, we’ll enhance the basic search scraper by visiting each app’s individual product page to extract deeper insights – such as the developer name, description, reviews, and ratings.
Once all apps are processed, the enriched dataset is written to a new CSV file containing all extracted fields. Here’s the complete code:
import requests
import csv
import json
import time
from bs4 import BeautifulSoup
from itertools import islice
import re
def enrich_play_store_apps(input_file='google_play_apps.csv', output_file='enriched_google_play_apps.csv', limit=None):
"""Enrich Google Play Store apps with detailed information from their pages"""
# Proxy setup
proxies = {
"http": "http://username:password@p.webshare.io:80",
"https": "http://username:password@p.webshare.io:80"
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
enriched_apps = []
with open(input_file, 'r', encoding='utf-8') as infile:
reader = csv.DictReader(infile)
rows = list(reader)
if limit:
rows = rows[:limit]
for i, row in enumerate(rows):
url = row.get('app_url', '').strip()
if not url or url == 'N/A':
continue
try:
print(f"Scraping [{i+1}/{len(rows)}]: {url}")
resp = requests.get(url, headers=headers, proxies=proxies, timeout=15)
resp.raise_for_status()
soup = BeautifulSoup(resp.content, 'html.parser')
# EXTRACT DEVELOPER NAME
developer_name = 'N/A'
dev_elem = soup.find('a', href=re.compile(r'/store/apps/developer\?id='))
if not dev_elem:
dev_elem = soup.find('div', string=re.compile(r'Developer'))
if dev_elem:
dev_elem = dev_elem.find_next_sibling('div')
if dev_elem:
developer_name = dev_elem.get_text(strip=True)
# EXTRACT DEVELOPER URL
developer_url = 'N/A'
dev_link = soup.find('a', href=re.compile(r'/store/apps/developer\?id='))
if dev_link and dev_link.get('href'):
developer_url = f"https://play.google.com{dev_link['href']}"
# EXTRACT DESCRIPTION
description = 'N/A'
desc_elem = soup.find('div', {'data-g-id': 'description'})
if not desc_elem:
desc_elem = soup.find('div', class_='bARER')
if not desc_elem:
# Try meta description
meta_desc = soup.find('meta', {'name': 'description'})
if meta_desc:
description = meta_desc.get('content', 'N/A')[:500]
if desc_elem:
description = desc_elem.get_text(strip=True)[:500]
# EXTRACT REVIEWS AVG (from detail page - more accurate)
reviews_avg = row.get('reviews_avg', 'N/A')
rating_elem = soup.find('div', class_=['TT9eCd', 'jILTFe'])
if rating_elem:
rating_text = rating_elem.get_text(strip=True)
rating_match = re.search(r'(\d+\.\d+)', rating_text)
if rating_match:
reviews_avg = rating_match.group(1)
# EXTRACT REVIEWS COUNT
reviews_count = 'N/A'
count_elem = soup.find('div', class_='EHUI5b')
if count_elem:
count_text = count_elem.get_text(strip=True)
count_match = re.search(r'([\d,]+[KMB]?)', count_text) # Handle formats like "897K"
if count_match:
reviews_count = count_match.group(1)
# Fallback for reviews count
if reviews_count == 'N/A':
# Look for pattern like "X reviews"
count_text = soup.get_text()
count_match = re.search(r'([\d,]+[KMB]?)\s+reviews', count_text)
if count_match:
reviews_count = count_match.group(1)
# EXTRACT RECENT REVIEWS
recent_reviews = extract_recent_reviews(soup)
# Create enriched app entry
enriched_app = {
'title': row.get('title', 'N/A'),
'app_url': url,
'cover_url': row.get('cover_url', 'N/A'),
'logo_url': row.get('logo_url', 'N/A'),
'price': row.get('price', 'Free'),
'developer_name': developer_name,
'developer_url': developer_url,
'description': description,
'reviews_avg': reviews_avg,
'reviews_count': reviews_count,
'recent_reviews': json.dumps(recent_reviews, ensure_ascii=False) if recent_reviews else '[]'
}
enriched_apps.append(enriched_app)
print(f" Enriched: {row.get('title', 'N/A')}")
print(f" Developer: {developer_name} | Rating: {reviews_avg} | Reviews: {reviews_count}")
except Exception as e:
print(f"Error scraping {url}: {e}")
# Still add the app with basic data
enriched_apps.append({
'title': row.get('title', 'N/A'),
'app_url': url,
'cover_url': row.get('cover_url', 'N/A'),
'logo_url': row.get('logo_url', 'N/A'),
'price': row.get('price', 'Free'),
'developer_name': 'N/A',
'developer_url': 'N/A',
'description': 'N/A',
'reviews_avg': row.get('reviews_avg', 'N/A'),
'reviews_count': 'N/A',
'recent_reviews': '[]'
})
# delay between requests
time.sleep(2)
# Write enriched data to CSV
with open(output_file, 'w', newline='', encoding='utf-8') as outfile:
fieldnames = [
'title', 'app_url', 'cover_url', 'logo_url', 'price',
'developer_name', 'developer_url', 'description',
'reviews_avg', 'reviews_count', 'recent_reviews'
]
writer = csv.DictWriter(outfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(enriched_apps)
print(f"\nEnrichment complete! {len(enriched_apps)} apps saved to {output_file}")
# Show summary
successful = len([app for app in enriched_apps if app['developer_name'] != 'N/A'])
print(f"Successfully enriched: {successful}/{len(enriched_apps)} apps")
return enriched_apps
def extract_recent_reviews(soup):
"""Extract recent reviews from the app page with fixed rating extraction"""
reviews = []
# Multiple selectors for review containers
review_selectors = ['div.RHo1pe', 'div[data-g-id]', 'div.SingleReview']
for selector in review_selectors:
review_containers = soup.select(selector)
for container in review_containers[:5]: # Get 5 most recent
try:
author = container.select_one('.X5PpBb')
date = container.select_one('.bp9Aid')
text = container.select_one('.h3YV2d')
# FIXED: Extract rating from aria-label attribute
review_rating = 'N/A'
rating_elem = container.select_one('.iXRFPc')
if rating_elem:
aria_label = rating_elem.get('aria-label', '')
rating_match = re.search(r'Rated\s+(\d+)\s+stars', aria_label)
if rating_match:
review_rating = rating_match.group(1)
# Alternative method: count the filled stars
if review_rating == 'N/A' and rating_elem:
filled_stars = rating_elem.select('.Z1Dz7b') # Filled stars
if filled_stars:
review_rating = str(len(filled_stars))
# Only add if we have meaningful content
if text and text.get_text(strip=True) and len(text.get_text(strip=True)) > 10:
reviews.append({
'author': author.get_text(strip=True) if author else 'Anonymous',
'date': date.get_text(strip=True) if date else 'N/A',
'rating': review_rating,
'text': text.get_text(strip=True)[:300]
})
except Exception as e:
print(f"Error parsing review: {e}")
continue
return reviews
# Alternative function with better element detection
def enrich_play_store_apps_detailed(input_file='google_play_apps.csv', output_file='enriched_google_play_apps.csv', limit=10):
"""More detailed enrichment with better element detection"""
proxies = {
"http": "http://username:password@p.webshare.io:80",
"https": "http://username:password@p.webshare.io:80"
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
enriched_apps = []
with open(input_file, 'r', encoding='utf-8') as infile:
reader = csv.DictReader(infile)
rows = list(reader)
if limit:
rows = rows[:limit]
for i, row in enumerate(rows):
url = row.get('app_url', '').strip()
if not url or url == 'N/A':
continue
try:
print(f"Scraping [{i+1}/{len(rows)}]: {row.get('title', 'Unknown')}")
resp = requests.get(url, headers=headers, proxies=proxies, timeout=15)
soup = BeautifulSoup(resp.content, 'html.parser')
# Extract all data using multiple methods
app_data = extract_app_data(soup, row)
enriched_apps.append(app_data)
print(f"{app_data['title']} | Dev: {app_data['developer_name']} | Reviews: {app_data['reviews_count']}")
except Exception as e:
print(f"Error: {e}")
enriched_apps.append(create_fallback_app(row))
time.sleep(1)
# Save to CSV
with open(output_file, 'w', newline='', encoding='utf-8') as outfile:
fieldnames = [
'title', 'app_url', 'cover_url', 'logo_url', 'price',
'developer_name', 'developer_url', 'description',
'reviews_avg', 'reviews_count', 'recent_reviews'
]
writer = csv.DictWriter(outfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(enriched_apps)
print(f"\nSaved {len(enriched_apps)} enriched apps to {output_file}")
return enriched_apps
def extract_app_data(soup, original_row):
"""Extract all app data from the detail page"""
# Developer info
developer_name = 'N/A'
developer_url = 'N/A'
dev_link = soup.find('a', href=re.compile(r'/store/apps/developer\?id='))
if dev_link:
developer_name = dev_link.get_text(strip=True)
developer_url = f"https://play.google.com{dev_link['href']}"
# Description
description = 'N/A'
desc_selectors = ['div[data-g-id="description"]', 'div.bARER', 'div.ClM7O']
for selector in desc_selectors:
desc_elem = soup.select_one(selector)
if desc_elem:
description = desc_elem.get_text(strip=True)[:500]
break
# Reviews average
reviews_avg = original_row.get('reviews_avg', 'N/A')
rating_elem = soup.select_one('div.TT9eCd, div.jILTFe')
if rating_elem:
rating_match = re.search(r'(\d+\.\d+)', rating_elem.get_text())
if rating_match:
reviews_avg = rating_match.group(1)
# Reviews count
reviews_count = 'N/A'
count_elem = soup.select_one('div.EHUI5b')
if count_elem:
count_match = re.search(r'([\d,]+[KMB]?)', count_elem.get_text())
if count_match:
reviews_count = count_match.group(1)
# Recent reviews
recent_reviews = extract_recent_reviews(soup)
return {
'title': original_row.get('title', 'N/A'),
'app_url': original_row.get('app_url', 'N/A'),
'cover_url': original_row.get('cover_url', 'N/A'),
'logo_url': original_row.get('logo_url', 'N/A'),
'price': original_row.get('price', 'Free'),
'developer_name': developer_name,
'developer_url': developer_url,
'description': description,
'reviews_avg': reviews_avg,
'reviews_count': reviews_count,
'recent_reviews': json.dumps(recent_reviews, ensure_ascii=False) if recent_reviews else '[]'
}
def create_fallback_app(row):
"""Create app entry with fallback data when scraping fails"""
return {
'title': row.get('title', 'N/A'),
'app_url': row.get('app_url', 'N/A'),
'cover_url': row.get('cover_url', 'N/A'),
'logo_url': row.get('logo_url', 'N/A'),
'price': row.get('price', 'Free'),
'developer_name': 'N/A',
'developer_url': 'N/A',
'description': 'N/A',
'reviews_avg': row.get('reviews_avg', 'N/A'),
'reviews_count': 'N/A',
'recent_reviews': '[]'
}
# Example usage
if __name__ == "__main__":
# Enrich apps from the CSV file
enrich_play_store_apps(
input_file='google_play_apps.csv',
output_file='enriched_google_play_apps.csv',
limit=20 # Used it for testing. You can remove this line to process all apps
)
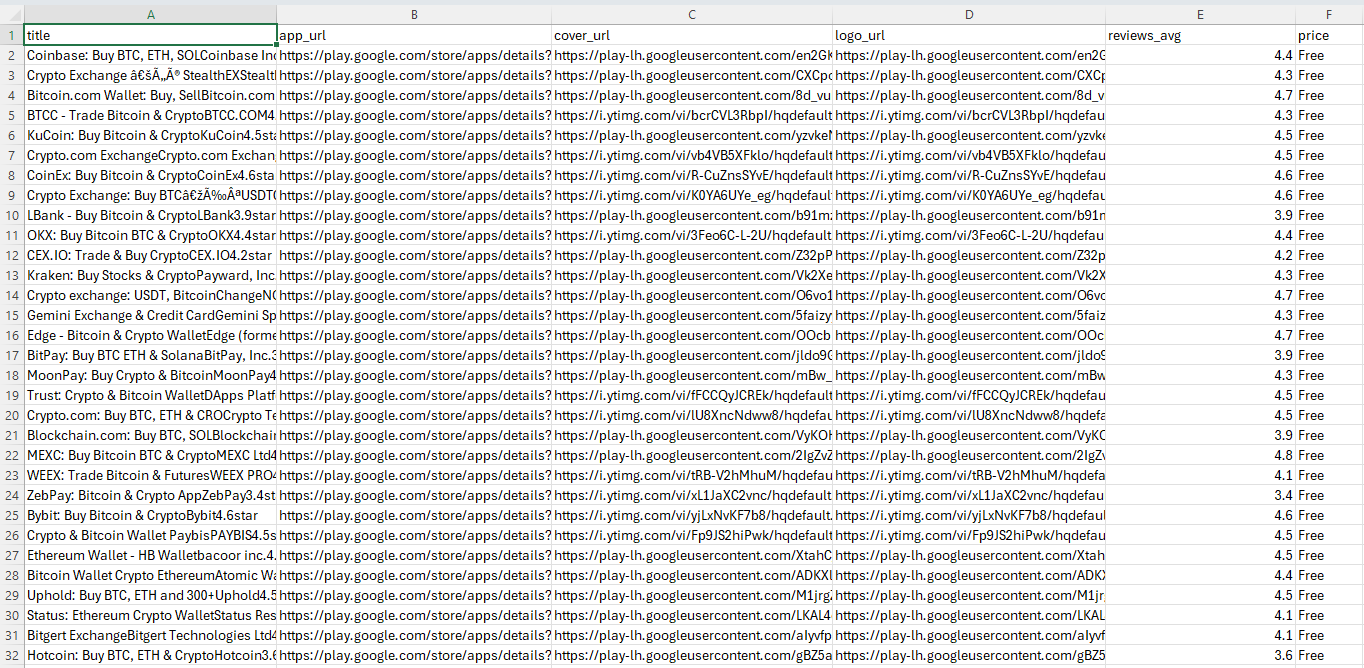
Here’s how the output looks like:

The generated csv is as:
Here’s the complete code:
import pandas as pd
import requests
from bs4 import BeautifulSoup
import json
import time
import random
import os
import re
import csv
class AdvancedGooglePlayReviewScraper:
def __init__(self):
self.proxies = {
"http": "http://username:password@p.webshare.io:80",
"https": "http://username:password@p.webshare.io:80"
}
self.session = requests.Session()
self.session.proxies.update(self.proxies)
# Comprehensive headers to mimic real browser
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Cache-Control': 'max-age=0',
'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
})
def parse_csv_correctly(self, csv_file_path):
"""Parse the CSV file correctly"""
apps = []
with open(csv_file_path, 'r', encoding='utf-8') as f:
reader = csv.reader(f, delimiter=',', quotechar='"')
# Skip header
next(reader, None)
for row in reader:
if len(row) >= 6:
app_data = {
'title': row[0].strip('"'),
'app_url': row[1].strip('"'),
'cover_url': row[2].strip('"'),
'logo_url': row[3].strip('"'),
'reviews_avg': row[4].strip('"'),
'price': row[5].strip('"')
}
apps.append(app_data)
return apps
def get_app_id_from_url(self, url):
"""Extract app ID from Google Play URL"""
try:
if 'id=' in url:
match = re.search(r'[?&]id=([^&]+)', url)
if match:
return match.group(1)
return None
except:
return None
def scrape_all_reviews_advanced(self, app_url, max_reviews=100):
"""Advanced method to scrape ALL reviews using multiple techniques"""
try:
app_id = self.get_app_id_from_url(app_url)
if not app_id:
print("Could not extract app ID")
return []
print(f"Advanced scraping for: {app_id}")
all_reviews = []
# Strategy 1: Try the "showAllReviews" parameter with different approaches
strategies = [
self.try_show_all_reviews,
self.try_reviews_api_endpoint,
self.try_different_languages,
self.try_country_variations,
self.try_review_feed
]
for strategy in strategies:
if len(all_reviews) >= max_reviews:
break
try:
reviews = strategy(app_id, max_reviews - len(all_reviews))
if reviews:
# Deduplicate reviews
for review in reviews:
if len(all_reviews) >= max_reviews:
break
review_key = f"{review['review_author']}_{review['review_date']}_{review['review_text'][:50]}"
if not any(r.get('_key') == review_key for r in all_reviews):
review['_key'] = review_key
all_reviews.append(review)
print(f"Strategy {strategy.__name__}: {len(reviews)} new reviews, total: {len(all_reviews)}")
time.sleep(2)
except Exception as e:
print(f"Strategy {strategy.__name__} failed: {e}")
continue
# Remove temporary keys
for review in all_reviews:
review.pop('_key', None)
print(f"✓ Total reviews scraped: {len(all_reviews)}")
return all_reviews
except Exception as e:
print(f"Error in advanced scraping: {e}")
return []
def try_show_all_reviews(self, app_id, max_reviews):
"""Try the showAllReviews parameter with various combinations"""
reviews = []
# Different parameter combinations
param_combinations = [
{'hl': 'en', 'gl': 'US', 'showAllReviews': 'true'},
{'hl': 'en', 'gl': 'US', 'showAllReviews': 'true', 'sort': 1},
{'hl': 'en', 'gl': 'US', 'showAllReviews': 'true', 'sort': 2},
{'hl': 'en', 'gl': 'US', 'showAllReviews': 'true', 'sort': 3},
{'hl': 'en', 'gl': 'US', 'showAllReviews': 'true', 'sort': 4},
]
for params in param_combinations:
if len(reviews) >= max_reviews:
break
try:
url = f"https://play.google.com/store/apps/details?id={app_id}"
response = self.session.get(url, params=params, timeout=30)
if response.status_code == 200:
batch_reviews = self.extract_reviews_aggressive(response.text)
for review in batch_reviews:
if len(reviews) >= max_reviews:
break
reviews.append(review)
print(f"Params {params}: {len(batch_reviews)} reviews")
time.sleep(1)
except Exception as e:
continue
return reviews[:max_reviews]
def try_reviews_api_endpoint(self, app_id, max_reviews):
"""Try to find and use the actual reviews API endpoint"""
reviews = []
try:
# First, get the main page to look for API clues
url = f"https://play.google.com/store/apps/details?id={app_id}&hl=en"
response = self.session.get(url, timeout=30)
if response.status_code == 200:
# Look for review data in the page source
soup = BeautifulSoup(response.text, 'html.parser')
# Look for script tags with review data
scripts = soup.find_all('script')
for script in scripts:
if script.string and 'review' in script.string.lower():
# Try to extract review data from script content
script_reviews = self.extract_reviews_from_script(script.string)
for review in script_reviews:
if len(reviews) >= max_reviews:
break
reviews.append(review)
print(f"Script extraction: {len(reviews)} reviews")
except Exception as e:
print(f"API endpoint method failed: {e}")
return reviews[:max_reviews]
def try_different_languages(self, app_id, max_reviews):
"""Try accessing the page in different languages"""
reviews = []
languages = ['en', 'es', 'fr', 'de', 'pt', 'ru', 'ja', 'ko', 'zh']
for lang in languages:
if len(reviews) >= max_reviews:
break
try:
url = f"https://play.google.com/store/apps/details?id={app_id}&hl={lang}&gl=US&showAllReviews=true"
response = self.session.get(url, timeout=30)
if response.status_code == 200:
batch_reviews = self.extract_reviews_aggressive(response.text)
for review in batch_reviews:
if len(reviews) >= max_reviews:
break
reviews.append(review)
print(f"Language {lang}: {len(batch_reviews)} reviews")
time.sleep(1)
except Exception as e:
continue
return reviews[:max_reviews]
def try_country_variations(self, app_id, max_reviews):
"""Try different country codes"""
reviews = []
countries = ['US', 'GB', 'CA', 'AU', 'IN', 'DE', 'FR', 'JP', 'KR', 'BR']
for country in countries:
if len(reviews) >= max_reviews:
break
try:
url = f"https://play.google.com/store/apps/details?id={app_id}&hl=en&gl={country}&showAllReviews=true"
response = self.session.get(url, timeout=30)
if response.status_code == 200:
batch_reviews = self.extract_reviews_aggressive(response.text)
for review in batch_reviews:
if len(reviews) >= max_reviews:
break
reviews.append(review)
print(f"Country {country}: {len(batch_reviews)} reviews")
time.sleep(1)
except Exception as e:
continue
return reviews[:max_reviews]
def try_review_feed(self, app_id, max_reviews):
"""Try to access the review feed directly"""
reviews = []
try:
# This is a more direct approach to get review data
url = f"https://play.google.com/store/apps/details?id={app_id}"
# Add headers that might trigger more data
headers = {
'X-Requested-With': 'XMLHttpRequest',
'Referer': f'https://play.google.com/store/apps/details?id={app_id}',
}
response = self.session.get(url, headers=headers, timeout=30)
if response.status_code == 200:
batch_reviews = self.extract_reviews_aggressive(response.text)
reviews.extend(batch_reviews)
print(f"Review feed: {len(batch_reviews)} reviews")
except Exception as e:
print(f"Review feed method failed: {e}")
return reviews[:max_reviews]
def extract_reviews_aggressive(self, html_content):
"""Aggressively extract reviews from HTML using multiple methods"""
reviews = []
soup = BeautifulSoup(html_content, 'html.parser')
# Method 1: Standard review containers
standard_containers = soup.find_all('div', class_=['RHo1pe', 'EGFGHd'])
for container in standard_containers:
review = self.parse_review_container(container)
if review:
reviews.append(review)
# Method 2: Look for any div that might contain review-like content
all_divs = soup.find_all('div')
for div in all_divs:
text = div.get_text(strip=True)
# Heuristic: if it has substantial text and mentions stars/reviews
if len(text) > 100 and any(keyword in text.lower() for keyword in ['star', 'review', 'rating']):
review = self.parse_review_from_text(text)
if review:
reviews.append(review)
# Method 3: Look for JSON-LD structured data
script_tags = soup.find_all('script', type='application/ld+json')
for script in script_tags:
try:
data = json.loads(script.string)
script_reviews = self.extract_reviews_from_structured_data(data)
reviews.extend(script_reviews)
except:
pass
return reviews
def parse_review_container(self, container):
"""Parse a single review container"""
try:
# AUTHOR
author_elem = container.select_one('.X5PpBb')
author = author_elem.get_text(strip=True) if author_elem else 'Anonymous'
# DATE
date_elem = container.select_one('.bp9Aid')
date = date_elem.get_text(strip=True) if date_elem else 'N/A'
# REVIEW TEXT
text_elem = container.select_one('.h3YV2d')
review_text = text_elem.get_text(strip=True) if text_elem else ''
if not review_text or len(review_text) < 10:
return None
# RATING
rating = self.extract_rating_from_container(container)
# HELPFUL COUNT
helpful_count = self.extract_helpful_count(container)
return {
"review_rating": rating,
"review_date": date,
"review_author": author,
"review_helpful": helpful_count,
"review_text": review_text
}
except Exception as e:
return None
def extract_rating_from_container(self, container):
"""Extract rating from review container"""
try:
rating_elem = container.select_one('.iXRFPc')
if rating_elem:
aria_label = rating_elem.get('aria-label', '')
rating_match = re.search(r'Rated\s+(\d+)\s+stars', aria_label)
if rating_match:
return int(rating_match.group(1))
if rating_elem:
filled_stars = rating_elem.select('.Z1Dz7b')
if filled_stars:
return len(filled_stars)
return 0
except:
return 0
def extract_helpful_count(self, container):
"""Extract helpful count from review container"""
try:
container_text = container.get_text()
helpful_match = re.search(r'(\d+)\s*people found this helpful', container_text)
if helpful_match:
return int(helpful_match.group(1))
return 0
except:
return 0
def extract_reviews_from_script(self, script_content):
"""Extract reviews from script content"""
reviews = []
# Look for review patterns in script content
review_patterns = [
r'"reviewText"\s*:\s*"([^"]+)"',
r'"text"\s*:\s*"([^"]+)"',
r'"description"\s*:\s*"([^"]+)"',
]
for pattern in review_patterns:
matches = re.findall(pattern, script_content)
for match in matches:
if len(match) > 20: # Substantial review text
reviews.append({
"review_rating": 0,
"review_date": "N/A",
"review_author": "Anonymous",
"review_helpful": 0,
"review_text": match
})
return reviews
def extract_reviews_from_structured_data(self, data):
"""Extract reviews from structured data"""
reviews = []
def extract_from_obj(obj):
if isinstance(obj, dict):
if 'reviewBody' in obj and isinstance(obj['reviewBody'], str):
rating = obj.get('reviewRating', {}).get('ratingValue', 0)
author = obj.get('author', {}).get('name', 'Anonymous')
date = obj.get('datePublished', 'N/A')
reviews.append({
"review_rating": int(rating) if rating else 0,
"review_date": date,
"review_author": author,
"review_helpful": 0,
"review_text": obj['reviewBody']
})
# Recursively search nested objects
for value in obj.values():
extract_from_obj(value)
elif isinstance(obj, list):
for item in obj:
extract_from_obj(item)
extract_from_obj(data)
return reviews
def parse_review_from_text(self, text):
"""Parse review from raw text using heuristics"""
try:
# Simple heuristic: if it looks like a review, create a basic review object
if len(text) > 50 and any(keyword in text.lower() for keyword in ['good', 'bad', 'great', 'poor', 'excellent', 'terrible']):
return {
"review_rating": 0,
"review_date": "N/A",
"review_author": "Anonymous",
"review_helpful": 0,
"review_text": text[:500] # Limit length
}
except:
pass
return None
def scrape_all_apps_reviews(self, csv_file_path, output_file='enriched_apps_with_all_reviews.json'):
"""Main function to scrape ALL reviews for all apps"""
try:
apps = self.parse_csv_correctly(csv_file_path)
print(f"Loaded {len(apps)} apps from {csv_file_path}")
enriched_data = []
for i, app_data in enumerate(apps):
try:
title = app_data['title']
app_url = app_data['app_url']
print(f"\n{'='*60}")
print(f"Processing app {i + 1}/{len(apps)}")
print(f"Title: {title[:50]}...")
app_id = self.get_app_id_from_url(app_url)
if not app_id:
print("Invalid URL, skipping...")
continue
app_entry = {
"title": title,
"app_url": app_url,
"cover_url": app_data['cover_url'],
"logo_url": app_data['logo_url'],
"reviews_avg": app_data['reviews_avg'],
"price": app_data['price'],
"reviews": []
}
# Use the advanced method to get ALL reviews
reviews = self.scrape_all_reviews_advanced(app_url, max_reviews=100)
app_entry["reviews"] = reviews
app_entry["total_reviews_scraped"] = len(reviews)
enriched_data.append(app_entry)
# Save progress
with open('progress_backup.json', 'w', encoding='utf-8') as f:
json.dump(enriched_data, f, indent=2, ensure_ascii=False)
print(f"✓ Completed: {len(reviews)} reviews")
delay = random.uniform(3, 6)
time.sleep(delay)
except Exception as e:
print(f"Error processing app: {e}")
continue
# Save final data
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(enriched_data, f, indent=2, ensure_ascii=False)
# Print summary
total_reviews = sum(app.get('total_reviews_scraped', 0) for app in enriched_data)
successful_apps = len([app for app in enriched_data if app.get('total_reviews_scraped', 0) > 0])
print(f"Apps processed: {len(enriched_data)}")
print(f"Apps with reviews: {successful_apps}")
print(f"Total reviews scraped: {total_reviews}")
return enriched_data
except Exception as e:
print(f"Error: {e}")
return []
def main():
scraper = AdvancedGooglePlayReviewScraper()
csv_file = "google_play_apps.csv"
if not os.path.exists(csv_file):
print(f"Error: CSV file '{csv_file}' not found!")
return
enriched_data = scraper.scrape_all_apps_reviews(csv_file)
if __name__ == "__main__":
main()The output looks like this:
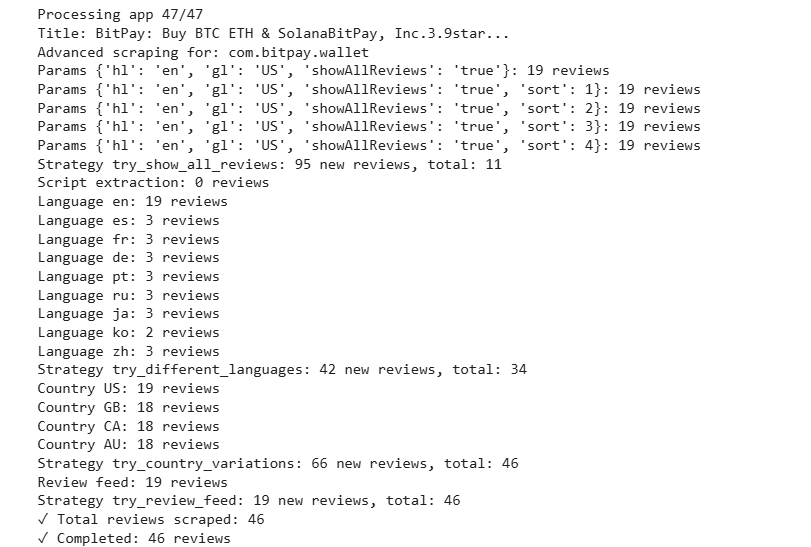

The generated json is as:

In this guide, we covered three methods: the first collects app search results, the second extracts detailed app info (name, developer, description, ratings) and initial reviews, and the third gathers all user reviews for full coverage. Use Webshare proxies, rotating headers, and other anti-detection methods plus polite delays to keep scraping reliable and minimize blocks.
