
Buy fast & affordable proxy servers. Get 10 proxies today for free.
Download our Proxy Server Extension
Products
© Webshare Proxy
payment methods





TL;DR
Google’s search results page offers valuable insights into user intent through its Related Searches and People Also Search For sections, which surface semantically connected topics and entities. In this guide, you’ll learn how to build a Python scraper that collects these suggestion datasets for any list of queries.
Before building and running the Google Related Searches scraper, make sure your environment is properly configured with the required tools and dependencies.
python --versionpip install playwrightplaywright install chromiumNow that your environment is ready, let’s walk through the process of scraping Google’s related searches and ‘People also search for’ sections step-by-step.
Once all queries are processed, compile your data into a structured dictionary that includes:
Write this structured data into a JSON file using Python’s json.dump() method with UTF-8 encoding and indentation for readability.
Note: This code uses await main() which works in Google Colab and Jupyter notebooks. For regular Python scripts, use this instead:
if __name__ == "__main__":
asyncio.run(main())Here’s the complete code:
import asyncio
from playwright.async_api import async_playwright
import json
import random
class GoogleRelatedSearchesScraper:
def __init__(self, proxy_details=None, proxy_location="US"):
self.results = []
self.proxy_details = proxy_details
self.proxy_location = proxy_location
async def setup_browser(self):
playwright = await async_playwright().start()
launch_args = [
'--no-sandbox',
'--disable-dev-shm-usage',
'--disable-blink-features=AutomationControlled',
]
if self.proxy_details:
proxy_server = self.proxy_details.split('@')[1]
launch_args.append(f'--proxy-server={proxy_server}')
browser = await playwright.chromium.launch(
headless=True,
args=launch_args
)
context_args = {
'viewport': {'width': 1366, 'height': 768},
'user_agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}
if self.proxy_details:
proxy_parts = self.proxy_details.split('://')[1].split('@')
if len(proxy_parts) == 2:
credentials = proxy_parts[0]
context_args['http_credentials'] = {
'username': credentials.split(':')[0],
'password': credentials.split(':')[1]
}
context = await browser.new_context(**context_args)
await context.add_init_script("""
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined,
});
""")
page = await context.new_page()
return playwright, browser, context, page
async def human_like_delay(self):
await asyncio.sleep(random.uniform(3, 6))
async def extract_related_searches(self, page, query):
related_searches = []
try:
search_box = await page.query_selector('textarea[name="q"]')
if search_box:
await search_box.click()
for char in query:
await search_box.press(char)
await asyncio.sleep(0.1)
await asyncio.sleep(2)
await page.wait_for_selector('.OBMEnb', timeout=8000)
suggestion_elements = await page.query_selector_all('.sbct .wM6W7d')
for element in suggestion_elements:
suggestion_text = await element.text_content()
if suggestion_text and suggestion_text.strip():
clean_text = suggestion_text.replace('\n', ' ').strip()
if clean_text.lower() != query.lower():
related_searches.append(clean_text)
await search_box.click(click_count=3)
await search_box.press('Backspace')
await asyncio.sleep(1)
except Exception as e:
print(f"Error extracting related searches for {query}: {e}")
return related_searches[:10]
async def extract_people_also_search_for(self, page, query):
people_also_search = []
try:
search_url = f"https://www.google.com/search?q={query.replace(' ', '+')}&gl=us&hl=en"
await page.set_extra_http_headers({
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'DNT': '1',
})
await page.goto(search_url, wait_until='networkidle', timeout=20000)
await asyncio.sleep(3)
current_url = page.url
if any(blocked in current_url for blocked in ['sorry', 'captcha', 'blocked']):
return people_also_search
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(2)
section_selectors = [
'div[aria-label="People also search for"]',
'div:has-text("People also search for")',
'.oIk2Cb',
'.MjjYud'
]
for selector in section_selectors:
section = await page.query_selector(selector)
if section:
item_selectors = ['.dg6jd', '.mtv5bd span']
for item_selector in item_selectors:
items = await section.query_selector_all(item_selector)
if items:
for item in items:
text = await item.text_content()
if text and text.strip():
clean_text = text.replace('\n', ' ').strip()
if clean_text not in people_also_search:
people_also_search.append(clean_text)
break
break
await page.goto('https://www.google.com', wait_until='networkidle')
except Exception as e:
print(f"Error extracting People also search for for {query}: {e}")
try:
await page.goto('https://www.google.com', wait_until='networkidle')
except:
pass
return people_also_search[:8]
async def scrape_related_searches(self, queries, enable_related_searches=True, enable_people_also_search=True):
playwright, browser, context, page = await self.setup_browser()
try:
await page.goto('https://www.google.com', wait_until='networkidle', timeout=30000)
await self.human_like_delay()
results = []
for query in queries:
print(f"Processing query: {query}")
query_result = {
'query': query,
'related_searches': [],
'people_also_search_for': []
}
if enable_related_searches:
related_searches = await self.extract_related_searches(page, query)
query_result['related_searches'] = related_searches
print(f"Found {len(related_searches)} related searches")
if enable_people_also_search:
people_also_search = await self.extract_people_also_search_for(page, query)
query_result['people_also_search_for'] = people_also_search
print(f"Found {len(people_also_search)} People also search for items")
results.append(query_result)
await self.human_like_delay()
return {
'search_queries': queries,
'proxy_location': self.proxy_location,
'results': results
}
except Exception as e:
print(f"Error during scraping: {e}")
return {
'search_queries': queries,
'proxy_location': self.proxy_location,
'results': [],
'error': str(e)
}
finally:
await browser.close()
await playwright.stop()
async def main():
PROXY_DETAILS = "http://username-rotate:password@p.webshare.io:80"
scraper = GoogleRelatedSearchesScraper(
proxy_details=PROXY_DETAILS,
proxy_location="US"
)
queries = [
"jk rowling",
"jrr tolkien",
"mark twain"
]
results = await scraper.scrape_related_searches(
queries=queries,
enable_related_searches=True,
enable_people_also_search=True
)
with open('google_related_searches.json', 'w', encoding='utf-8') as f:
json.dump(results, f, indent=2, ensure_ascii=False)
print("Scraping completed")
print(f"Processed {len(results['results'])} queries")
await main()Here’s the console output:

The generated json is as:
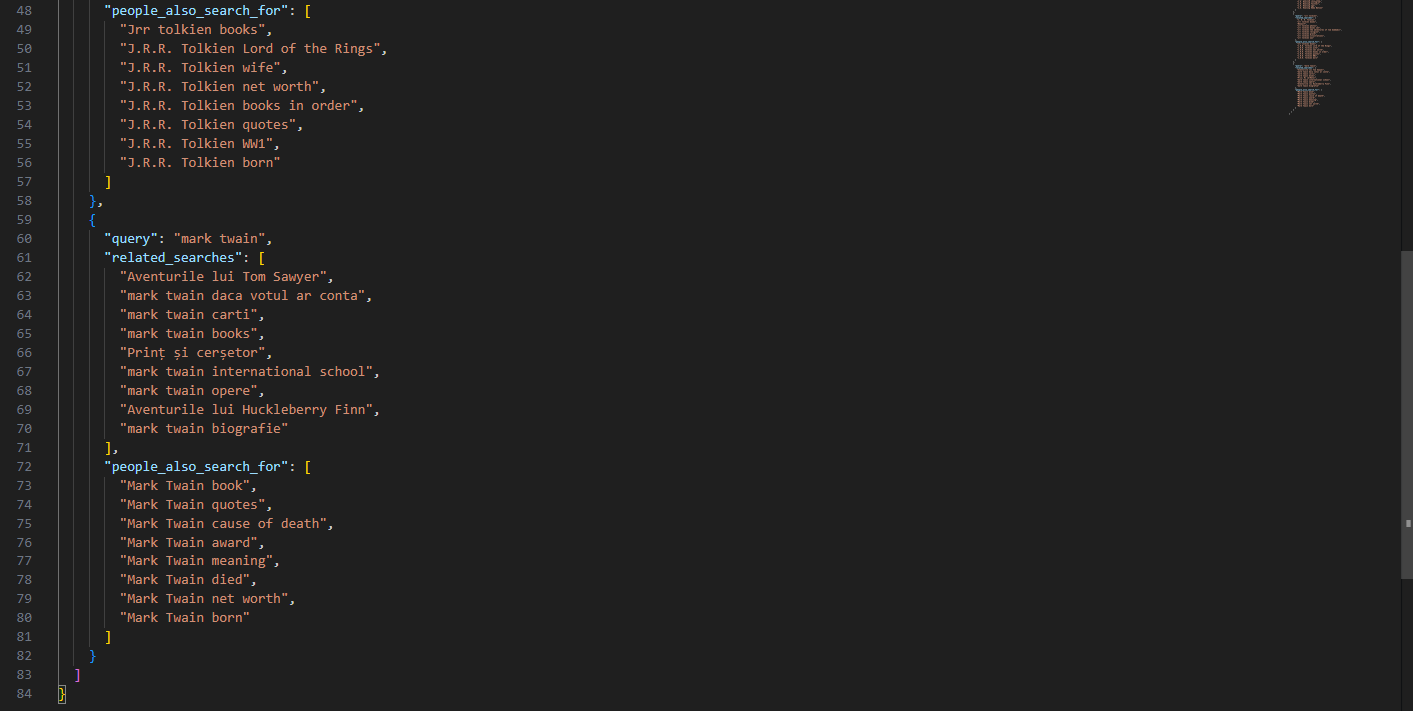
This guide demonstrates how to collect Google’s related searches and ‘People also search for’ data using Playwright and Webshare rotating residential proxies. The scraper automates browser interactions, handles JavaScript-rendered content, and adapts to different geographic regions through proxy-based location targeting. The resulting solution captures two key categories of contextual data – search bar suggestions and post-search related entities – while maintaining stability and avoiding detection.
