
Buy fast & affordable proxy servers. Get 10 proxies today for free.
Download our Proxy Server Extension
Products
© Webshare Proxy
payment methods





TL;DR
Google Search Ads is one of the most competitive and data-rich advertising platforms, displaying targeted sponsored results above and below organic listings based on search intent, location, and bidding strategy. In this guide, you’ll learn how to build a Google Search Ads scraper in Python that captures structured ad data for a search query.
Before building and running the Google Search Ads scraper, make sure your environment is properly configured with the required tools and dependencies.
python --versionpip install playwrightplaywright install chromiumNow that you’ve set up your environment, let’s walk through the process of scraping ad data using Python and Playwright.
Next, define an asynchronous method setup_browser() to launch a headless Chromium browser using Playwright.
After launching, create a browser context with a realistic viewport and user-agent to mimic a human user. Also, disable resource-heavy elements (like images and fonts) to improve performance and reduce bandwidth usage.
Add two helper functions inside your class:
Create an asynchronous method called scrape_ads(search_query). This function will:
You’ll then iterate through each ad container and call another function (extract_ad_data) to collect details about individual ads.
Define the extract_ad_data() method to capture relevant ad information from each ad block.
For each ad element:
Once extracted, store all these details in a structured dictionary containing fields like:
main_url, domain, meta_title, meta_description, display_url, and ad_location.
In your main() function:
Once all queries are processed, close the browser with await scraper.close().
Finally, write the extracted data to a JSON file for easy analysis and reuse. Here’s the complete code:
import asyncio
import json
from urllib.parse import urlparse, parse_qs
from playwright.async_api import async_playwright
class GoogleAdsScraper:
def __init__(self):
self.browser = None
self.page = None
async def setup_browser(self, use_proxy=True):
playwright = await async_playwright().start()
launch_options = {
'headless': True,
'args': [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-blink-features=AutomationControlled',
'--disable-dev-shm-usage'
]
}
if use_proxy:
proxy_config = {
'server': 'http://p.webshare.io:80',
'username': 'username-rotate', # your username
'password': 'password' # your password
}
launch_options['proxy'] = proxy_config
self.browser = await playwright.chromium.launch(**launch_options)
context = await self.browser.new_context(
viewport={'width': 1920, 'height': 1080},
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
)
await context.add_init_script("""
Object.defineProperty(navigator, 'webdriver', {get: () => undefined});
""")
self.page = await context.new_page()
await self.page.route("**/*", lambda route: route.abort()
if route.request.resource_type in ["image", "font"]
else route.continue_())
def extract_domain(self, url):
try:
parsed = urlparse(url)
return parsed.netloc.replace('www.', '')
except:
return url
def clean_google_url(self, url):
"""Extract actual URL from Google redirect"""
if not url:
return ""
# Handle /aclk? redirects (Google Ads)
if '/aclk?' in url:
try:
parsed = urlparse(url)
query_params = parse_qs(parsed.query)
# Get the actual URL from adurl parameter
actual_url = query_params.get('adurl', [None])[0]
if actual_url:
return actual_url
except:
pass
return url
async def scrape_ads(self, search_query):
try:
search_url = f"https://www.google.com/search?q={search_query.replace(' ', '+')}&gl=us"
await self.page.goto(search_url, wait_until='networkidle', timeout=60000)
await asyncio.sleep(3)
ads_data = {
"search_query": search_query,
"top_ads": [],
"bottom_ads": []
}
# Find all ad containers
ad_containers = await self.page.query_selector_all('[data-text-ad="1"]')
for container in ad_containers:
ad_data = await self.extract_ad_data(container, "top")
if ad_data:
ads_data["top_ads"].append(ad_data)
return ads_data
except Exception as e:
print(f"Error: {e}")
return None
async def extract_ad_data(self, ad_element, ad_location):
try:
# Get position
position = await ad_element.get_attribute('data-ta-slot-pos')
if not position:
position = "0"
# Get main URL
link_element = await ad_element.query_selector('a[href]')
if not link_element:
return None
main_url = await link_element.get_attribute('href')
if not main_url:
return None
# Clean Google redirect URL to get actual destination
original_url = main_url
main_url = self.clean_google_url(main_url)
# Extract domain from the cleaned URL
domain = self.extract_domain(main_url) if main_url else ""
# Get title - try multiple selectors
title_selectors = [
'.CCgQ5 .vCa9Yd span',
'.vCa9Yd span',
'[role="heading"] span',
'.CCgQ5 span'
]
meta_title = ""
for selector in title_selectors:
title_element = await ad_element.query_selector(selector)
if title_element:
meta_title = await title_element.text_content()
if meta_title and meta_title.strip():
break
# Get description
desc_element = await ad_element.query_selector('.p4wth')
meta_description = await desc_element.text_content() if desc_element else ""
# Get display URL (the URL shown to users)
display_url_element = await ad_element.query_selector('.x2VHCd.OSrXXb.ob9lvb')
display_url = await display_url_element.text_content() if display_url_element else ""
# If unable to extract title, try to get it from the link text
if not meta_title:
meta_title = await link_element.text_content() or ""
ad_data = {
"position": int(position) if position.isdigit() else 0,
"main_url": main_url, # Actual destination URL
"domain": domain, # Extracted from main_url
"display_url": display_url,
"meta_title": meta_title.strip(),
"meta_description": meta_description.strip(),
"ad_location": ad_location
}
# Only return if we have valid data
if ad_data["main_url"] and ad_data["domain"]:
return ad_data
return None
except Exception as e:
print(f"Error extracting ad: {e}")
return None
async def close(self):
if self.browser:
await self.browser.close()
async def main():
search_queries = ["plumbing new york"]
scraper = GoogleAdsScraper()
await scraper.setup_browser(use_proxy=True)
all_results = []
for query in search_queries:
print(f"Scraping: {query}")
result = await scraper.scrape_ads(query)
if result:
all_results.append(result)
print(f"Found {len(result['top_ads'])} top ads")
await scraper.close()
with open('google_ads_results.json', 'w', encoding='utf-8') as f:
json.dump(all_results, f, indent=2, ensure_ascii=False)
print("Results saved to google_ads_results.json")
return all_results
await main()
Note: This code uses await main() which works in Google Colab and Jupyter notebooks. If you’re running it as a standalone Python script, replace the last line with:
if __name__ == "__main__":
asyncio.run(main())
Here’s the console output:
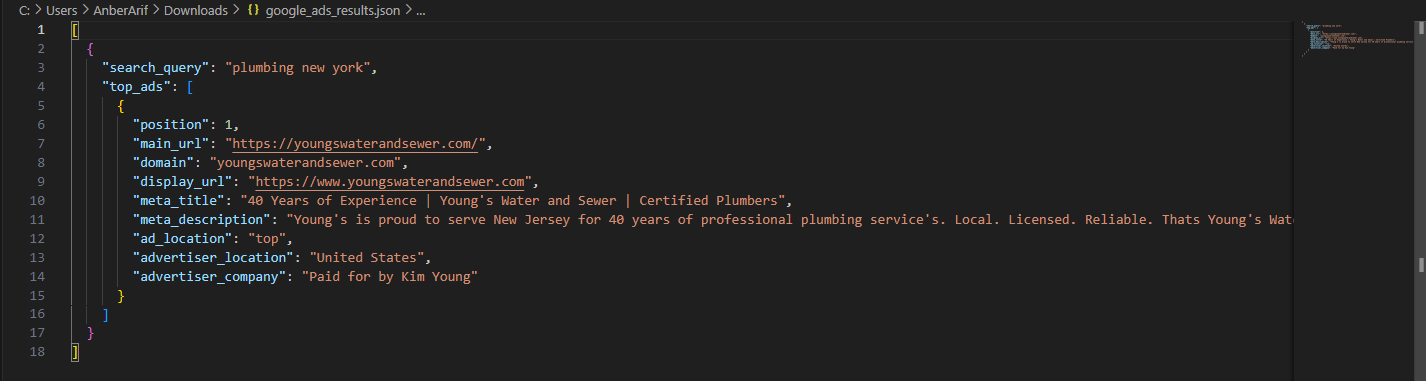
The generated json is as:
Scraping Google Ads Transparency Data (Optional)
For more advanced use cases, here's the code that includes an optional transparency scraping toggle to extract additional advertiser information from Google's transparency tab:
import asyncio
import json
from urllib.parse import urlparse, parse_qs
from playwright.async_api import async_playwright
class GoogleAdsScraper:
def __init__(self, scrape_transparency=False):
self.browser = None
self.page = None
self.scrape_transparency = scrape_transparency
async def setup_browser(self, use_proxy=True):
playwright = await async_playwright().start()
launch_options = {
'headless': True,
'args': [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-blink-features=AutomationControlled',
'--disable-dev-shm-usage'
]
}
if use_proxy:
proxy_config = {
'server': 'http://p.webshare.io:80',
'username': 'username-rotate',
'password': 'password'
}
launch_options['proxy'] = proxy_config
self.browser = await playwright.chromium.launch(**launch_options)
context = await self.browser.new_context(
viewport={'width': 1920, 'height': 1080},
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
)
await context.add_init_script("""
Object.defineProperty(navigator, 'webdriver', {get: () => undefined});
""")
self.page = await context.new_page()
await self.page.route("**/*", lambda route: route.abort()
if route.request.resource_type in ["image", "font"]
else route.continue_())
def extract_domain(self, url):
try:
parsed = urlparse(url)
return parsed.netloc.replace('www.', '')
except:
return url
def clean_google_url(self, url):
"""Extract actual URL from Google redirect"""
if not url:
return ""
# Handle /aclk? redirects (Google Ads)
if '/aclk?' in url:
try:
parsed = urlparse(url)
query_params = parse_qs(parsed.query)
# Get the actual URL from adurl parameter
actual_url = query_params.get('adurl', [None])[0]
if actual_url:
return actual_url
except:
pass
return url
async def check_and_handle_consent_dialog(self):
"""Check for and handle consent dialog if it appears"""
try:
# Check if consent dialog is currently visible (non-blocking check)
consent_dialog = await self.page.query_selector('#xe7COe, [aria-label*="Before you continue to Google Search"]')
if consent_dialog:
print("Found consent dialog, handling it...")
# Try to click reject button quickly
reject_button = await self.page.query_selector('button:has-text("Reject all")')
if reject_button:
await reject_button.click()
await asyncio.sleep(2)
return True
# If no reject button, try escape
await self.page.keyboard.press('Escape')
await asyncio.sleep(1)
return True
return False
except Exception as e:
print(f"Error checking consent dialog: {e}")
return False
async def find_ads_with_retry(self, max_retries=2):
"""Find ads with multiple selector strategies and retries"""
ad_selectors = [
'[data-text-ad="1"]', # Primary selector
'.uEierd', # Ad container
'.ads-ad', # Generic ad class
'.v5yQqb', # Another ad container
'[data-hveid]', # Generic ad indicator
]
for attempt in range(max_retries):
print(f"Attempt {attempt + 1} to find ads...")
for selector in ad_selectors:
try:
ads = await self.page.query_selector_all(selector)
if ads:
# Filter to only those that look like actual ads
filtered_ads = []
for ad in ads:
ad_html = await ad.inner_html()
ad_text = await ad.text_content()
# Check if this looks like an ad
if any(indicator in ad_html.lower() or indicator in ad_text.lower()
for indicator in ['ad', 'sponsored', 'call', 'visit', 'www.', 'http']):
filtered_ads.append(ad)
if filtered_ads:
print(f"Found {len(filtered_ads)} ads with selector: {selector}")
return filtered_ads
except Exception as e:
print(f"Error with selector {selector}: {e}")
# If no ads found, wait and retry
if attempt < max_retries - 1:
print("No ads found, waiting 3 seconds and retrying...")
await asyncio.sleep(3)
print("No ads found after all attempts")
return []
async def scrape_advertiser_transparency(self, ad_element):
"""Optional: Scrape advertiser info from ad transparency tab"""
if not self.scrape_transparency:
return {"advertiser_location": "", "advertiser_company": ""}
try:
# Click on the "Why this ad?" button to open transparency dialog
why_ad_button = await ad_element.query_selector('[title="Why this ad?"]')
if why_ad_button:
# Use JavaScript click to avoid pointer event issues
await self.page.evaluate("(element) => { element.click(); }", why_ad_button)
await asyncio.sleep(3)
advertiser_company = ""
advertiser_location = ""
# Wait for the transparency dialog to load
try:
await self.page.wait_for_selector('#ucc-1, .dQaeVb', timeout=5000)
except:
print("Transparency dialog didn't load properly")
# Close dialog and return empty data
await self.page.keyboard.press('Escape')
await asyncio.sleep(1)
return {"advertiser_location": "", "advertiser_company": ""}
# Look for transparency data
transparency_containers = await self.page.query_selector_all('.dQaeVb')
for container in transparency_containers:
# Get the label
label_element = await container.query_selector('.DyyDHe')
if label_element:
label_text = await label_element.text_content()
# Get the value
value_element = await container.query_selector('.xZhkSd')
if value_element:
value_text = await value_element.text_content()
# Match the exact labels we're looking for
if label_text.strip() == 'Advertiser':
advertiser_company = value_text
print(f"Found advertiser: {advertiser_company}")
elif label_text.strip() == 'Location':
advertiser_location = value_text
print(f"Found location: {advertiser_location}")
# Close the transparency dialog
await self.page.keyboard.press('Escape')
await asyncio.sleep(1)
return {
"advertiser_location": advertiser_location.strip(),
"advertiser_company": advertiser_company.strip()
}
return {"advertiser_location": "", "advertiser_company": ""}
except Exception as e:
print(f"Transparency scraping failed: {e}")
# Try to close any open dialogs
try:
await self.page.keyboard.press('Escape')
await asyncio.sleep(1)
except:
pass
return {"advertiser_location": "", "advertiser_company": ""}
async def scrape_ads(self, search_query):
try:
search_url = f"https://www.google.com/search?q={search_query.replace(' ', '+')}&gl=us"
print(f"Navigating to: {search_url}")
await self.page.goto(search_url, wait_until='networkidle', timeout=60000)
await asyncio.sleep(3)
# Initial consent check
await self.check_and_handle_consent_dialog()
ads_data = {
"search_query": search_query,
"top_ads": []
}
# Find ads with retry logic
ad_containers = await self.find_ads_with_retry(max_retries=2)
for i, container in enumerate(ad_containers):
print(f"Processing ad {i+1}/{len(ad_containers)}")
ad_data = await self.extract_ad_data(container, "top")
if ad_data:
ads_data["top_ads"].append(ad_data)
return ads_data
except Exception as e:
print(f"Error: {e}")
return None
async def extract_ad_data(self, ad_element, ad_location):
try:
# Get position
position = await ad_element.get_attribute('data-ta-slot-pos')
if not position:
position = "0"
# Get main URL
link_element = await ad_element.query_selector('a[href]')
if not link_element:
return None
main_url = await link_element.get_attribute('href')
if not main_url:
return None
# Clean Google redirect URL to get actual destination
main_url = self.clean_google_url(main_url)
# Extract domain from the CLEANED URL
domain = self.extract_domain(main_url) if main_url else ""
# Get title - try multiple selectors
title_selectors = [
'.CCgQ5 .vCa9Yd span',
'.vCa9Yd span',
'[role="heading"] span',
'.CCgQ5 span'
]
meta_title = ""
for selector in title_selectors:
title_element = await ad_element.query_selector(selector)
if title_element:
meta_title = await title_element.text_content()
if meta_title and meta_title.strip():
break
# Get description
desc_element = await ad_element.query_selector('.p4wth')
meta_description = await desc_element.text_content() if desc_element else ""
# Get display URL (the URL shown to users)
display_url_element = await ad_element.query_selector('.x2VHCd.OSrXXb.ob9lvb')
display_url = await display_url_element.text_content() if display_url_element else ""
# If unable to extract title, try to get it from the link text
if not meta_title:
meta_title = await link_element.text_content() or ""
# Extract transparency data if enabled
transparency_data = await self.scrape_advertiser_transparency(ad_element)
ad_data = {
"position": int(position) if position.isdigit() else 0,
"main_url": main_url, # Actual destination URL
"domain": domain, # Extracted from main_url
"display_url": display_url,
"meta_title": meta_title.strip(),
"meta_description": meta_description.strip(),
"ad_location": ad_location,
**transparency_data # Include transparency data if scraped
}
# Only return if we have valid data
if ad_data["main_url"] and ad_data["domain"]:
return ad_data
return None
except Exception as e:
print(f"Error extracting ad: {e}")
return None
async def close(self):
if self.browser:
await self.browser.close()
async def main():
search_queries = ["plumbing new york"]
# Toggle this to enable/disable transparency scraping
scrape_transparency = True
scraper = GoogleAdsScraper(scrape_transparency=scrape_transparency)
await scraper.setup_browser(use_proxy=True)
all_results = []
for query in search_queries:
print(f"Scraping: {query}")
result = await scraper.scrape_ads(query)
if result:
all_results.append(result)
print(f"Found {len(result['top_ads'])} top ads")
# Print transparency data if enabled
if scrape_transparency:
for ad in result['top_ads']:
print(f"Position {ad['position']}: {ad['domain']}")
if ad.get('advertiser_company'):
print(f" Company: {ad['advertiser_company']}")
else:
print(f" Company: Not found")
if ad.get('advertiser_location'):
print(f" Location: {ad['advertiser_location']}")
else:
print(f" Location: Not found")
else:
print("No results found")
all_results.append({"search_query": query, "top_ads": []})
await scraper.close()
with open('google_ads_results.json', 'w', encoding='utf-8') as f:
json.dump(all_results, f, indent=2, ensure_ascii=False)
print("Results saved to google_ads_results.json")
return all_results
await main()This code includes an optional transparency scraping toggle that extracts advertiser information directly from Google's “Why this ad?” dialog. When the scrape_transparency parameter is set to True, the scraper automatically clicks on each ad’s transparency button, opens the information panel, and extracts the verified advertiser company name and geographic location as shown in the below output:
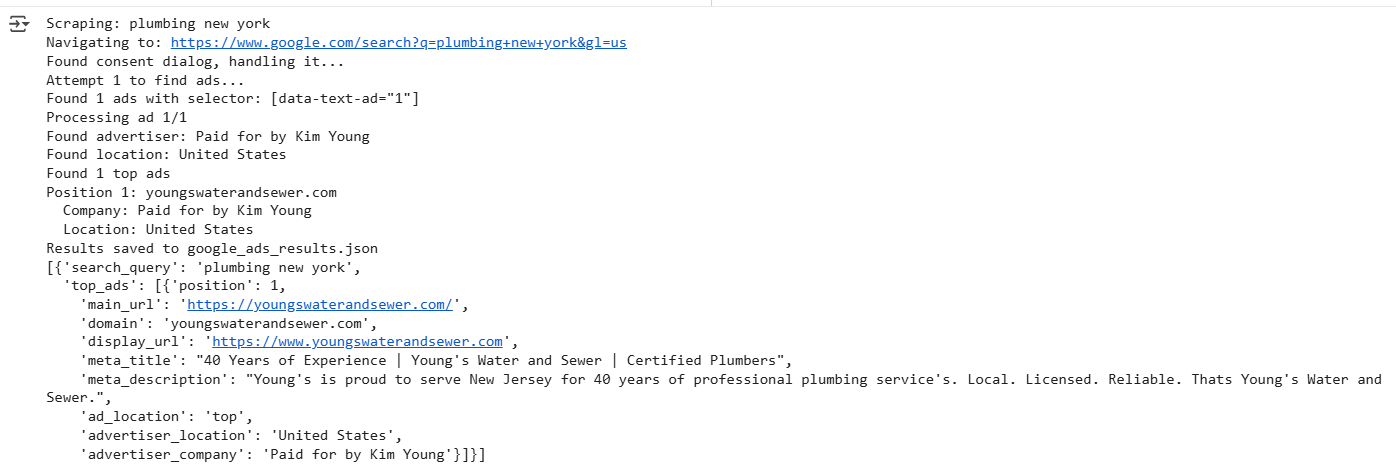
The generated json is as:
In this guide, we built a Google Ads scraper using Playwright and Webshare rotating residential proxies to extract sponsored ad data directly from Google Search results. The scraper captures key ad insights – including the main URL, domain, meta title, and meta description – for each search query while maintaining accuracy across different locations through proxy-based targeting. We also implemented an optional transparency scraping feature that, when enabled, collects additional details such as the advertiser’s company name and location from the “Why this ad?” section.
